Operations
Governance-by-design,
in production.
We don't hand over the code and walk away. The same Swiss discipline that shapes our delivery shapes how we operate systems day-to-day — documented controls, independent monitoring, audited changes, tested recovery.
Stance
Operate, don't just ship.
Business-critical workloads run 24/7 across borders. We own the system in production — not just the artefacts we shipped.
Independent observability.
System metrics, application logs and uptime are monitored on three separate planes — one of them external — so a single failure can't silence its own alarm.
Tested recovery, not promised.
Encrypted daily backups paired with quarterly restore tests against customer-defined RTO/RPO. Recovery is rehearsed before it's needed.
Measured operational uptime across hosted workloads.
Concurrent users on a federal collaboration platform we operate.
Cross-border, business-critical workflows in continuous operation.
Detection latency for newly disclosed CVEs in monitored stacks.
Reference architecture
A blueprint
we already run in production.
The stack below is not aspirational. It powers production systems we run today — including the platform behind a billing and identity backbone for a federal collaboration environment for 4,000 users.
Edge
Nginx reverse proxy
Load balancer
HTTPS · TLS
Orchestration
Kubernetes (production scale)
Docker containers
Portainer (container management)
Application
App server (backend)
Push messaging API
Domain APIs (transport, workspace)
Data
PostgreSQL
Encrypted daily backups
Quarterly restore tests
Delivery
GitHub / GitLab
GitLab CI/CD pipelines
Private container registry
Runtime languages
Backend: Python (~90%) / JavaScript
ERP base (multi-version)
iOS Swift · Android Kotlin
Topology
One picture,
three planes of truth.
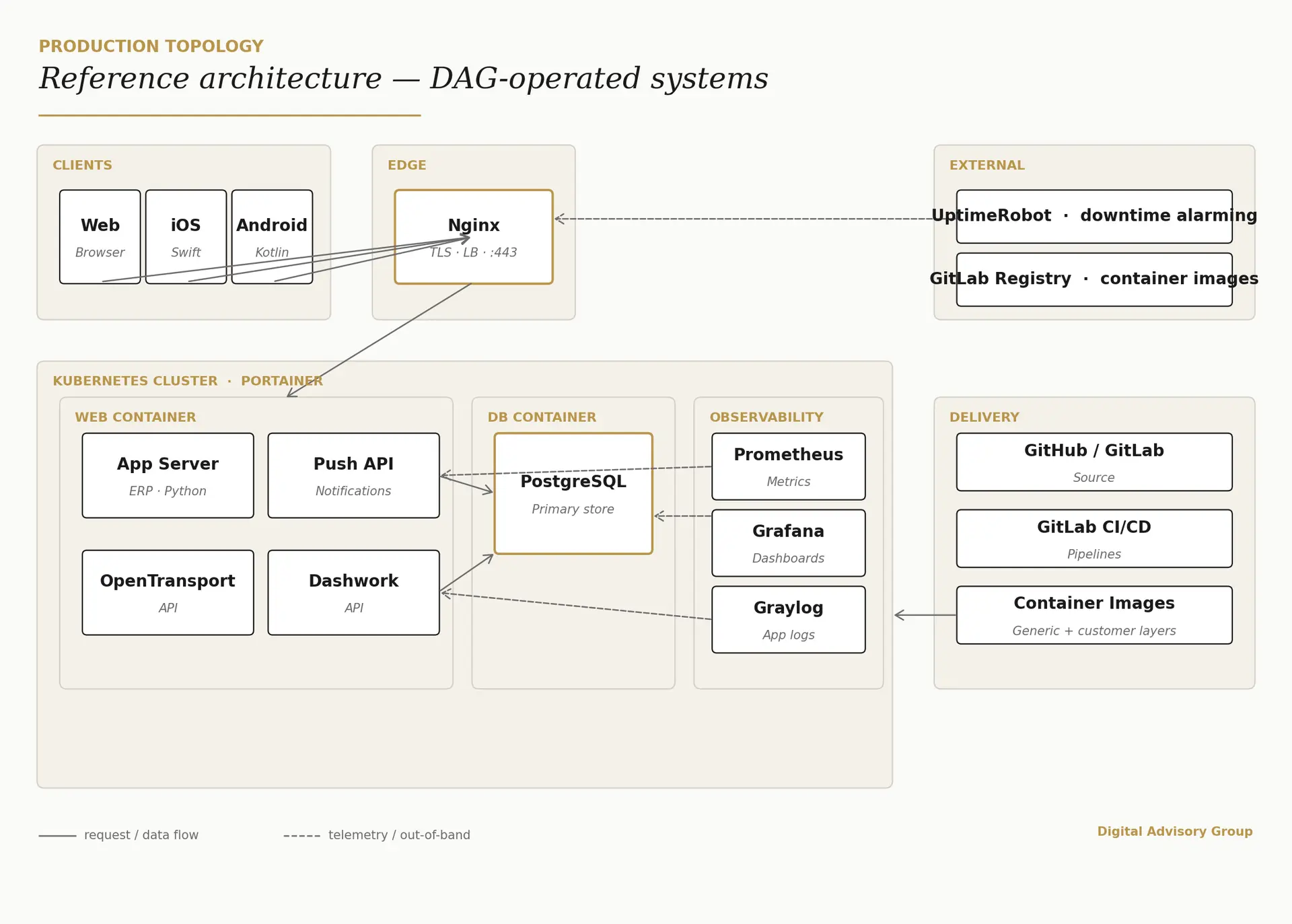
Production traffic flows top-to-bottom through the runtime spine on the left. Observability lives on its own plane on the right — and the uptime probe sits outside the perimeter, so a platform-wide outage cannot silence its own alarm.
Observability
Three planes.
One cannot silence the others.
Application logs
Greylog
Centralised, searchable, retained. Engineering and operations work from the same evidence trail the moment something drifts.
System metrics
Prometeus & Grafana
CPU, memory, disk and service-level signals from every container. Self-hosted alongside the workload, owned by us.
Uptime alarming
Externer Probe-Service
Independent of the hosting environment — a platform-wide outage cannot silence its own alarms. The first responder is paged regardless.
Quality & change
The paper trail
is the product.
Governance is not a slide. It is the documented, auditable path that work travels from commit to customer environment — and the evidence we capture along the way.
Quality management system
QMS v1.1, CEO-owned, with documented DR/BCP and a formal quality manual.
Audit cadence
Annual independent internal audit. Findings tracked to closure with verified effectiveness.
Change management
Git-based. Audited commit history, peer review on every change, GitLab CI/CD with an automated test pyramid (unit, integration, security).
Incident handling
24–48 hour customer notification on non-conformities. Formal CAPA loop — corrective action, preventive action, effectiveness check.
Retention
10-year retention for contracts and core delivery records. Vendor governance applied to every external dependency.
Disaster recovery
Encrypted daily backups. Quarterly restore tests against customer-defined RTO and RPO.
Security & privacy
Designed for
regulated environments.
Identity & access
MFA / SSO across systems. Role-based access control. Privileged access reviewed on a regular cadence.
Authentication
Two-factor on application access — via email or in-app QR. SSL across app, web and backend (BIT-issued certificate).
Secure SDLC
Vulnerability scanning wired into CI/CD. Vulnerable components cannot be promoted. Continuous SBOM-driven dependency monitoring.
Customer-data hygiene
No customer data on internet-connected DAG devices. Customer assets stay in customer-controlled environments by policy — not by goodwill.
Want this running
for your platform?
We can take operational ownership of an existing system or stand up a new platform on the same reference architecture and quality controls.