Betrieb
Governance-by-Design,
in Produktion.
Wir übergeben nicht den Code und gehen. Dieselbe Disziplin, die unsere Delivery prägt, prägt auch, wie wir Systeme im Alltag betreiben – dokumentierte Kontrollen, unabhängiges Monitoring, auditierte Changes, getestete Wiederherstellung.
Haltung
Betreiben statt nur ausliefern.
Geschäftskritische Workloads, 24/7 grenzüberschreitend betrieben. Wir verantworten das System in Produktion – nicht nur die ausgelieferten Artefakte.
Unabhängige Observability.
System-Metriken, Application-Logs und Uptime werden auf drei getrennten Ebenen überwacht – eine davon extern – damit ein einzelner Ausfall sich nicht selbst verstecken kann.
Getestetes, nicht versprochenes Recovery.
Verschlüsselte tägliche Backups, gepaart mit quartalsweisen Restore-Tests gegen kundendefinierte RTO/RPO. Recovery wird geprobt, bevor sie gebraucht wird.
Gemessene operative Verfügbarkeit über gehostete Workloads.
Gleichzeitige Nutzer auf einer von uns betriebenen föderalen Kollaborationsplattform.
Grenzüberschreitende, geschäftskritische Workflows in kontinuierlichem Betrieb.
Erkennungs-Latenz für neu veröffentlichte CVEs in überwachten Stacks.
Referenz-Architektur
Ein Blueprint,
den wir bereits betreiben.
Der untenstehende Stack ist nicht aspirativ. Er treibt Produktivsysteme an, die wir heute betreiben – inklusive der Plattform hinter einem Billing- und Identity-Backbone für 50+ KMU und einer föderalen Kollaborationsumgebung mit 4’000 Nutzern.
Edge
Nginx Reverse Proxy
Load Balancer
HTTPS · TLS (BIT-Zertifikat)
Orchestrierung
Kubernetes (Produktiv-Skalierung)
Docker-Container
Portainer (Container-Management)
Anwendung
App-Server (Backend)
Push-Messaging-API
Domain-APIs (Transport, Workspace)
Daten
PostgreSQL
Verschlüsselte tägliche Backups
Quartalsweise Restore-Tests
Delivery
GitHub / GitLab
GitLab CI/CD-Pipelines
Private Container-Registry
Laufzeit-Sprachen
Backend: Python (~90 %) / JavaScript
ERP-Basis (Multi-Version)
iOS Swift · Android Kotlin
Topologie
Ein Bild,
drei Ebenen der Wahrheit.
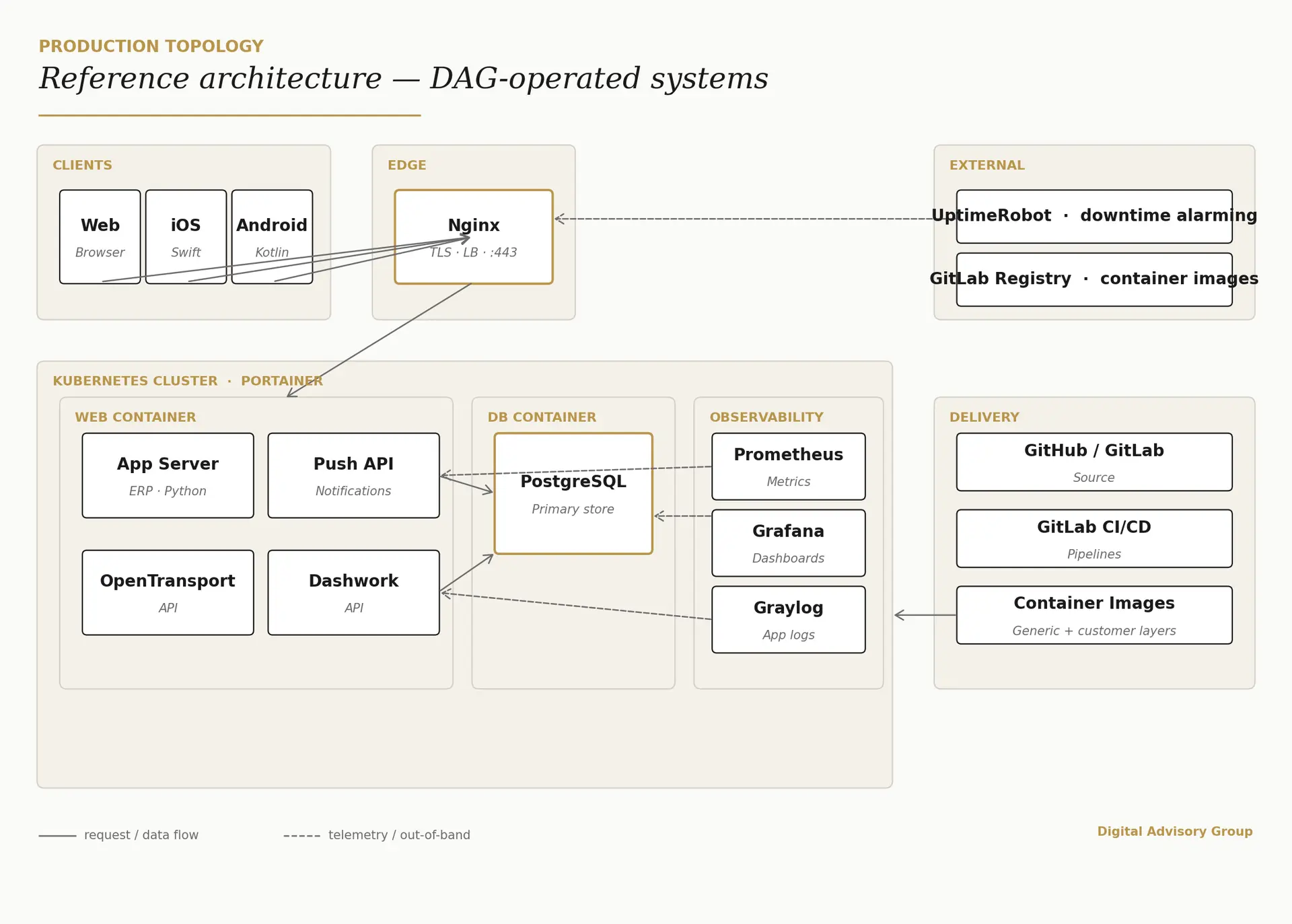
Produktiver Traffic fliesst von oben nach unten durch die Runtime-Spine links. Observability lebt auf einer eigenen Ebene rechts – und der Uptime-Probe sitzt ausserhalb des Perimeters, sodass ein plattformweiter Ausfall seinen eigenen Alarm nicht stummschalten kann.
Observability
Drei Ebenen.
Eine kann die anderen nicht stummschalten.
Application-Logs
Greylog
Zentralisiert, durchsuchbar, aufbewahrt. Engineering und Betrieb arbeiten mit demselben Evidenz-Trail, sobald etwas abweicht.
System-Metriken
Prometeus & Grafana
CPU, Speicher, Disk und Service-Level-Signale aus jedem Container. Selbst-gehostet neben dem Workload, von uns verantwortet.
Uptime-Alarming
Externer Probe-Service
Unabhängig von der Hosting-Umgebung – ein plattformweiter Ausfall kann seine eigenen Alarme nicht stummschalten. Der Erstreagierende wird in jedem Fall alarmiert.
Qualität & Change
Der Papier-Trail
ist das Produkt.
Governance ist keine Folie. Sie ist der dokumentierte, auditierbare Weg, wie Arbeit von einem Commit in eine Kundenumgebung wandert – und die Nachweise, die wir dabei sichern.
Qualitätsmanagement-System
QMS v1.1, CEO-verantwortet, mit dokumentiertem DR/BCP und einem formalen Qualitätshandbuch.
Audit-Takt
Jährliches unabhängiges internes Audit. Findings werden bis zur Schliessung mit verifizierter Wirksamkeit nachverfolgt.
Change Management
Git-basiert. Auditierter Commit-Verlauf, Peer-Reviews bei jeder Änderung, GitLab CI/CD mit automatisierter Test-Pyramide (Unit, Integration, Security).
Incident-Management
24–48 Stunden Kunden-Benachrichtigung bei Nicht-Konformitäten. Formale CAPA-Schleife – Korrekturmassnahme, Vorbeugemassnahme, Wirksamkeitsprüfung.
Aufbewahrung
10-Jahres-Aufbewahrung für Verträge und zentrale Delivery-Aufzeichnungen. Lieferanten-Governance auf jede externe Abhängigkeit angewendet.
Desaster Recovery
Verschlüsselte tägliche Backups. Quartalsweise Restore-Tests gegen kundendefinierte RTO und RPO.
Sicherheit & Datenschutz
Entworfen für
regulierte Umgebungen.
Identitäten & Zugriff
MFA / SSO über Systeme hinweg. Rollenbasierte Zugriffskontrolle. Privilegierte Zugriffe regelmässig überprüft.
Authentifizierung
Zwei-Faktor beim Anwendungszugriff – per E-Mail oder In-App-QR. SSL über App, Web und Backend (BIT-ausgestelltes Zertifikat).
Secure SDLC
Vulnerability-Scanning in CI/CD integriert. Verwundbare Komponenten können nicht promoted werden. Kontinuierliches SBOM-gestütztes Dependency-Monitoring.
Hygiene Kundendaten
Keine Kundendaten auf internetverbundenen DAG-Geräten. Kundeneigentum bleibt per Richtlinie in kundenseitig kontrollierten Umgebungen – nicht aus Goodwill.
Möchten Sie das laufend
für Ihre Plattform?
Wir können die operative Verantwortung für ein bestehendes System übernehmen oder eine neue Plattform auf derselben Referenzarchitektur und denselben Qualitätskontrollen aufsetzen.